Kubernetes – Almacenamiento con Linstor.
Hace ya un tiempo que escribí sobre k8s, otros proyectos han tomado tiempo y recursos, hace unas semanas retome el clúster que tengo en casa para terminar las configuraciones necesarias y mover lo más que pueda de algunas máquinas virtuales que tengo en vSphere y que entiendo desempeñarían mejor estando en Kubernetes.
Inicialmente las pruebas fueron realizadas con longhorn, algunos problemas los cuales no inspiran mucha confianza me hicieron no escribir sobre esa implementación, claramente Rancher dice que es un proyecto aun en beta.
Hace unas semanas leí sobre Linstor [ http://vitobotta.com/2019/08/07/linstor-storage-with-kubernetes/ ], la instalación fue realizada en Ubuntu que es la misma distribución que estoy usando. He decidido usar esta implementación porque usa LVM como backend en los equipos que aportaran almacenamiento para el clúster, además de esto los nodos que están aportando almacenamiento no necesariamente deben tener k8s, al menos eso es lo que entiendo y algo que debo validar.
Instalando Linstor.
Prepararemos nuestros equipos con los siguientes pasos:
apt-get install linux-headers-$(uname -r)
add-apt-repository ppa:linbit/linbit-drbd9-stack
apt-get update
apt install drbd-utils drbd-dkms lvm2
modprobe drbd
lsmod | grep -i drbd
echo drbd > /etc/modules-load.d/drbd.conf
En este punto ya los equipos están listos para instalar los componentes de Linstor. Para estar seguro de que todo estaba bien procedí a reiniciar el nodo.
Seleccionamos un equipo para que sea controlador del cluster de Linstor, además este mismo equipo puede aportar almacenamiento así que también instalaremos el componente de satellite.
apt install linstor-controller linstor-satellite linstor-client
Ahora habilitamos e inicializamos los componentes.
systemctl enable --now linstor-controller
systemctl start linstor-controller
En los demás equipos instalamos el componente de satélite.
apt install linstor-satellite linstor-client
Habilitamos el servicio y lo iniciamos.
systemctl enable --now linstor-satellite
systemctl start linstor-satellite
Desde el controller agregamos los equipos satélites.
linstor node create kube1 172.22.35.25
linstor node create kube2 172.22.35.26
linstor node create kube3 172.22.35.27
Esperamos unos minutos y ejecutamos:
linstor node list
Este comando nos mostrará la lista de nodos disponibles, será algo así:
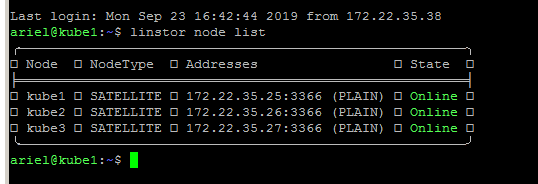
Ya contamos con un clúster de Linstor pero aun no estamos presentando almacenamiento a este, procederemos a crear almacenamiento administrado por LVM, Linstor soporta ZFS, esta es una herramienta que nunca he usado en el pasado de manera seria así que prefiero LVM que tiene años disponible en las distribuciones Linux.
En cada máquina virtual para Kubernetes agregue dos discos, uno para el sistema operativo y otro para almacenamiento que ahora será usado en su totalidad con Linstor.
Lo primero es preparar el disco físico para ser usado en LVM.
pvcreate /dev/sdb
Luego creamos un volumen group (vg).
vgcreate kube /dev/sdb
He seleccionado kube para que sea el nombre del Volume Group.
Procederemos a crear un thin pool, esto nos permitirá crear volúmenes más grandes que el espacio físico del cual disponemos.
lvcreate -l 100%FREE --thinpool kube/lvmthinpool
Una vez realizados estos pasas en cada nodo que aportara almacenamiento al cluster, volvemos al controller para crear un storage-pool.
linstor storage-pool create lvmthin kube1 linstor-pool kube/lvmthinpool
linstor storage-pool create lvmthin kube2 linstor-pool kube/lvmthinpool
linstor storage-pool create lvmthin kube3 linstor-pool kube/lvmthinpool
validamos que nuestro storage-pool fue creado.
linstor storage-pool list
Debemos recibir lo siguiente:

Listo, ya contamos con una plataforma para provisionar almacenamiento a Kubernetes, lo interesante es que también podría provisionar almacenamiento a otras plataformas tales como Proxmox.
Kubernetes – que necesitamos?
Para habilitar que Kubernetes pueda usar almacenamiento proveniente de Linstor, debemos contar con el plugin CSI y crear StorageClass, recomiendo tener una versión de Kubernetes mínimo 1.13 para que todo funcione bien ya que ahí plugins que no están habilitados por defecto antes de esta versión. Al momento de crear los CRD estos fallaban con un mensaje que especificaba la falta de CSINodeInfo, actualizando RKE a 1.14.6 se resolvió.
Instalaremos todo lo necesario para usar Linstor usando esta línea la cual descargar la versión 0.7.2 del CSI y usando sed estamos cambian un valor de ejemplo por el controlador de Linstor que en mi caso es 172.22.35.25. Esto debe ser ejecutado en la misma maquina de donde administramos k8s.
curl https://raw.githubusercontent.com/LINBIT/linstor-csi/v0.7.0/examples/k8s/deploy/linstor-csi-1.14.yaml | sed "s/linstor-controller.example.com/172.22.35.25/g" | kubectl apply -f -
Podemos ver el avance del de la instalación con:
watch kubectl -n kube-system get all
Procederemos a crear un Storage Class usando este yaml
El número de réplicas debe ser el número de nodos de Kubernetes.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: linstor
provisioner: linstor.csi.linbit.com
parameters:
autoPlace: "3"
storagePool: "linstor-pool"
Para este punto ya podemos hacer solicitudes de volúmenes usando un PresistentVolumeClaim
En mi caso ya tenia varios yaml con requerimientos de pvc, aquí uno.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
namespace: services
name: adguard-config
spec:
storageClassName: linstor
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi

Podemos ver que el STATUS es Bound, esto quiere decir que satisfactoriamente Linstor asigno espacio a Kubernetes para este volumen.
Desde el punto de vista de Linstor usando
linstor volume list
Podemos ver lo siguiente:
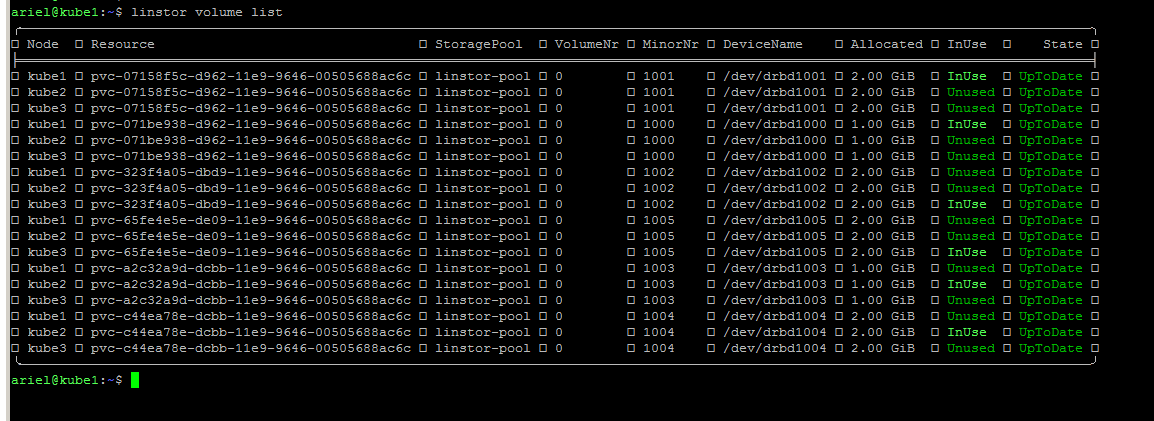
Estos son todos los volúmenes que están siendo usados por contenedores en Kubernetes.
Listo!
Ya puedo usar el cluster de Kubernetes, bueno por la cantidad de volúmenes que se ven en la imagen se puede deducir que lo estoy usando. He movido varios servicios hacia el clúster y hasta ahora muy feliz con Kubernetes.
El próximo paso es los respaldos, para esto estaré usando Velero de Heptio/VMware.



