Let’s do this.
I think this is the second English-post in the entire history of this blog. Be gentle with me.
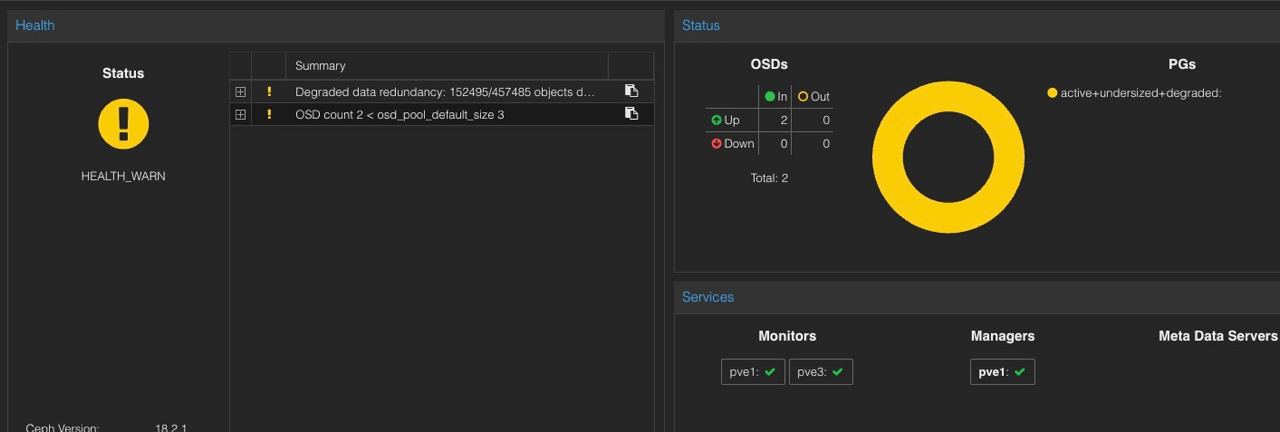
KubeVirt, is a known name for the people already doing containers, a normal player for people in the OpenShift world, but why if you come from others environment (VMware?) is like this doesn’t exist or is just being ignore?
If you can read Spanish and go back in the post history of this site, you can see that when is about VMs, VMware was the only option, not the same with Kubernetes, I started playing with K8s since 2018 and by that time, VMware didn’t have an offering that can compete with K8s. so I stick with K8s installed directly with kubeadm or the Rancher’s offering (RKE, RKE2 and K3s).
Why did I do a little recap?
Because is time to start trying new solutions to manage our VMs.
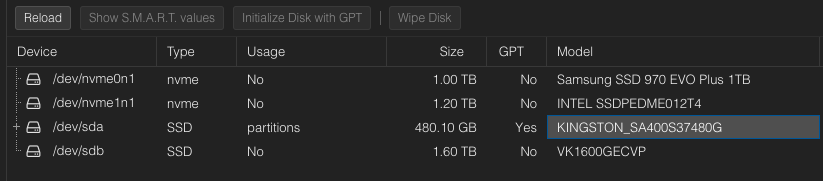
I love Harvester, love the fact that it can connect to Rancher UI and can be managed from the same place that I already have my containers, but is so resource intensive! The same host that was running Proxmox and ESXi can’t cope with the demand, I hope that this solution keeps growing and get my hands on others! (looking at you Platform9!).
My next steps, read more about plain KubeVirt to know more how this thing works behind the nice UI provided by Rancher or OpenShift… wish me luck !