Kubernetes – usando Rancher 2.0 para crear y administrar clusters de k8s!
Desde hace semanas estoy jugando con Kubernetes. La idea inicial ha sido armar un cluster usando herramientas nativas de k8s (kubeadm), de esta forma aprendería el funcionamiento base de la plataforma, lo gracioso es que pensé que lo estaba haciendo “de la manera difícil”, pero creo que no era así. Al parecer existe la manera “The hard way” la cual asusta por el simple hecho que todas las configuraciones e instalaciones son de manera manual, sin usar herramientas que autogeneran como es el caso de kubeadm. Al final, la razón de realizar la instalación de esta manera es con fin educativos, es recomendable conocer el porqué de las cosas.
Kubernetes the hard way.
https://github.com/kelseyhightower/kubernetes-the-hard-way
Con Kubernetes, aprender como funcionan los componentes se ha alargado más de la cuenta ya que el ecosistema es inmenso, y cada vez que pensé “Ya está instalado, ahora a desplegar algunos contenedores”, me topaba con que tenía que instalar otras herramientas antes de (¡nginx-ingress, te miro a ti!). otro factor fue que intente mezclar arquitecturas, quería tener adm64 y arm64.
Por ejemplo, cuando ya tenía el cluster creado, surgió la necesidad de acceder a las aplicaciones desde el exterior (¿Internet?), esto se resuelve muy fácil, Ingress Controller! Luego tenemos el tema del almacenamiento y así surgieron otras necesidades que cubrir para tener una solución que funcionara completamente.
Ya había escuchado (leído…) de esta plataforma, al principio me había confundido y pensaba que era de pago también la había confundido con RancherOS, este es un Linux con lo necesario para correr contenedores, igual que CoreOS.
Rancher es una plataforma para la administración de cluster de Kubernetes, esto es así en la versión 2.0, está basada totalmente en Kubernetes.
Instalando Rancher.
La instalación de esta plataforma es tan sencilla como correr cualquier otro Docker container, leyendo en Quick Start Guide, podemos ver que se usa Docker run para inicializar el contenedor. En mi caso he agregado varios valores que no están en la guía de inicio.
docker run -d –restart=unless-stopped -p 80:80 -p 443:443 -v /var/lib/rancher:/var/lib/rancher rancher/rancher:latest –acme-domain rancher.aanetworks.org
-v /var/lib/rancher:/var/lib/rancher
Luego de varios días de usar Rancher, me toco reiniciar el contenedor y para mi sorpresa perdí todos los cambios que había hecho, todo muy básico, pero es poco alentador ver algo así. Resulta que toda la configuración generada por etcd es almacenada en /var/lib/rancher/ junto a otras informaciones de la plataforma.
–acme-domain rancher.aanetworks.org
Luego de la aparición de Let’s Encrypt, ¡porque no tener SSL en los dominios de acceso público o privados!
Con esta línea conseguimos que Rancher solicite un SSL para el dominio que usaremos con la plataforma, debemos tener los puertos 80 y 443 accesible desde Internet para que proceda la validación de dicho dominio.
Esperamos varios minutos (5?) y luego procedemos a acceder al portal de administración, en mi caso es https://rancher.aanetworks.org, lo primero que recibiremos es un mensaje solicitando un cambio de password para el usuario admin, luego de especificar el password, tendremos acceso a la plataforma.
Clusters!
La primera opción ofrecida por Rancher luego de hacer login es la creación de un cluster, a diferencia de la versión 1.x la cual no he usado, la versión 2.0 ofrece crear clusters de Kubernetes o importarlos si ya se tiene alguno.
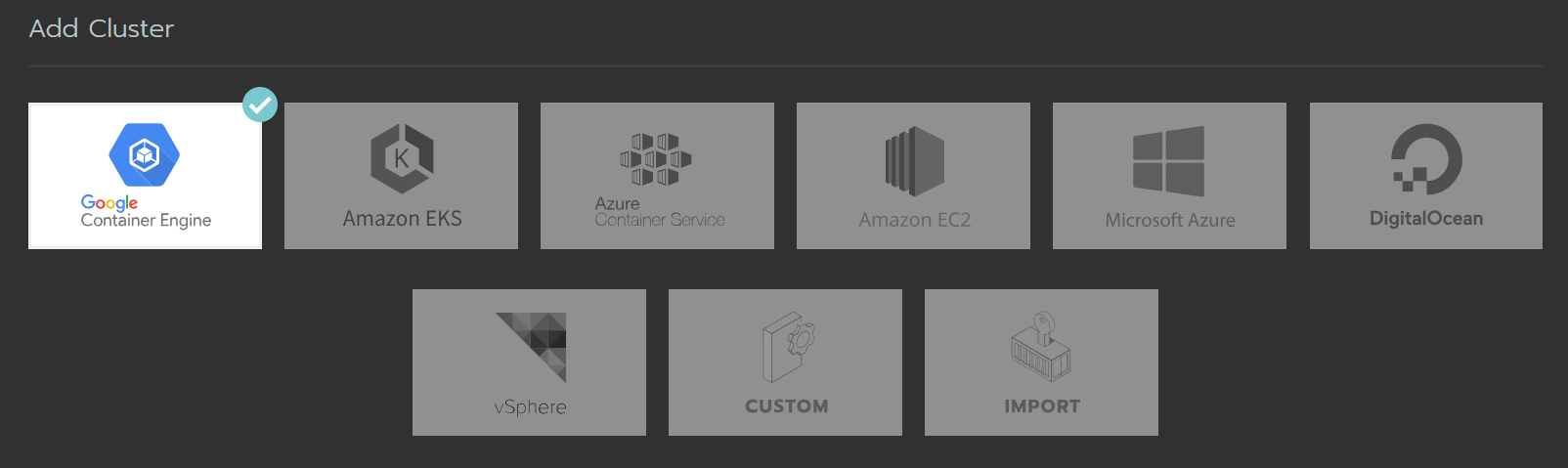
Tenemos opción de crear Google Kubernetes Engine (GKE), Amazon EKS, Azure Container Service (AKS), hasta se puede conectar con Digital Ocean para provisionar VM allí y agregarlas a un cluster. Por el momento solo he podido jugar con la integración de vSphere y Custom. En caso de Custom, luego de crear el cluster, se nos entrega un comando docker run para ser ejecutado en los nodos que deseamos agregar, estos ya deben tener una versión de Linux soportada junto a docker en una de las versiones soportadas.
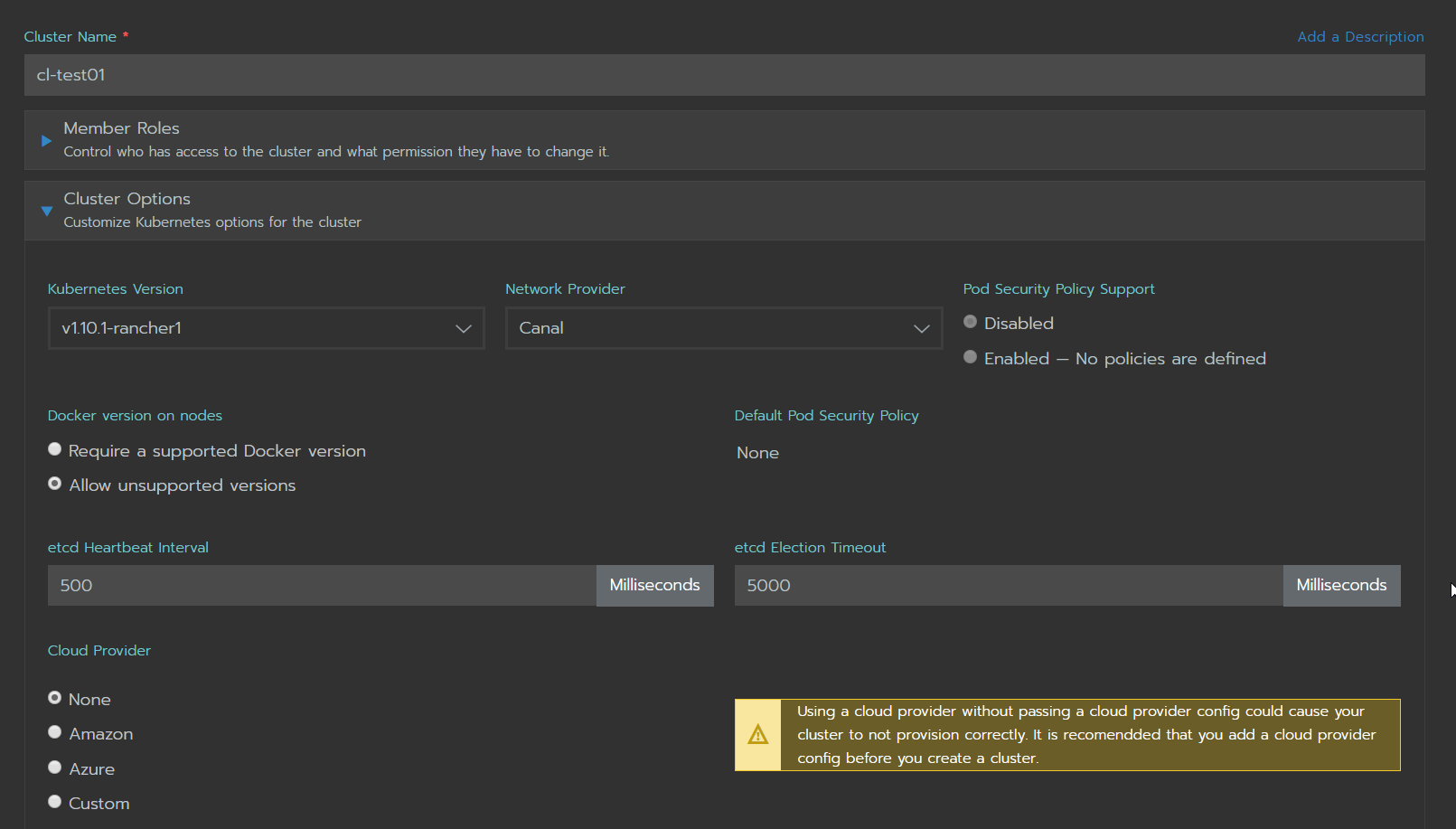
En esta captura se pueden ver las opciones ofrecidas por Rancher para la creación de un cluster tipo Custom.
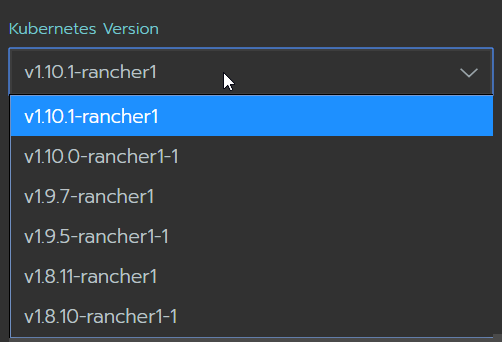
En la versión 2.0 GA, se disponen de las versiones de Kubernetes listadas aqui para ser desplegadas a los nodos.
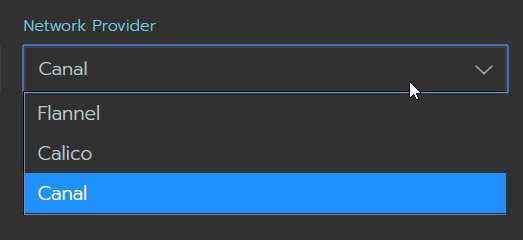
Como CNI (Container Network Interface) tenemos Flannel, Calico y Canal. Tengo entendido que Canal es una mezcla entre Flannel y Calico. Me gustaría que en lo adelante agregaran wave, aunque entiendo que necesito investigar más sobre Canal.
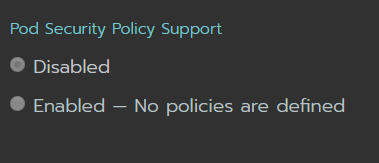
Pod Security, aún no he usado esta opción, entiendo que es un mecanismo para controlar el acceso a pods cuando están en namespace diferentes.

Rancher publica una lista de versiones de Docker soportadas, pero en la creación del cluster podemos elegir si deseamos que las versiones no soportadas puedan ser usadas.
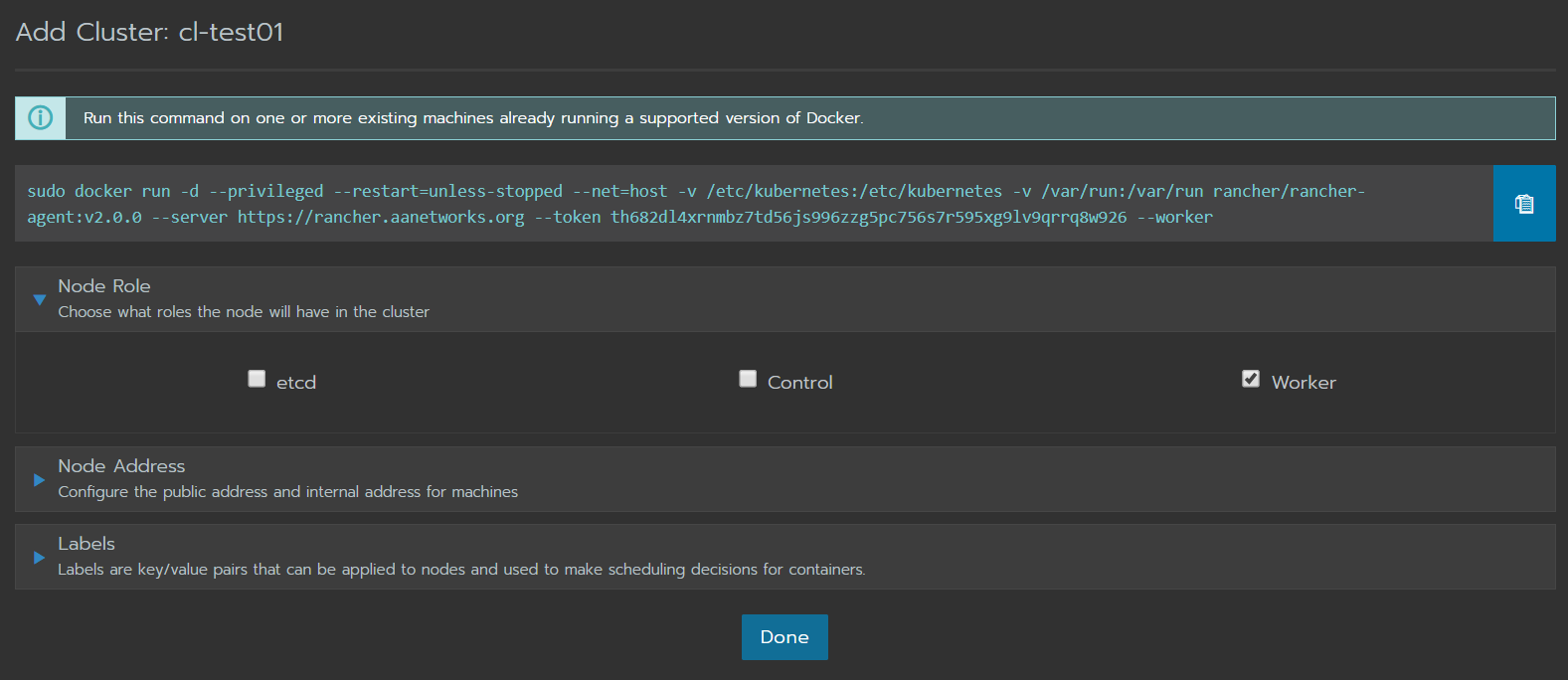
Podemos ver en el mensaje, debemos ejecutar ese docker run en uno o más servidores que deseamos formen parte de este cluster.
Node Role, necesitamos al menos un etcd, un control y un worker para comenzar a jugar con este cluster, los siguientes equipos que agreguemos al cluter pueden tener el role de Worker.
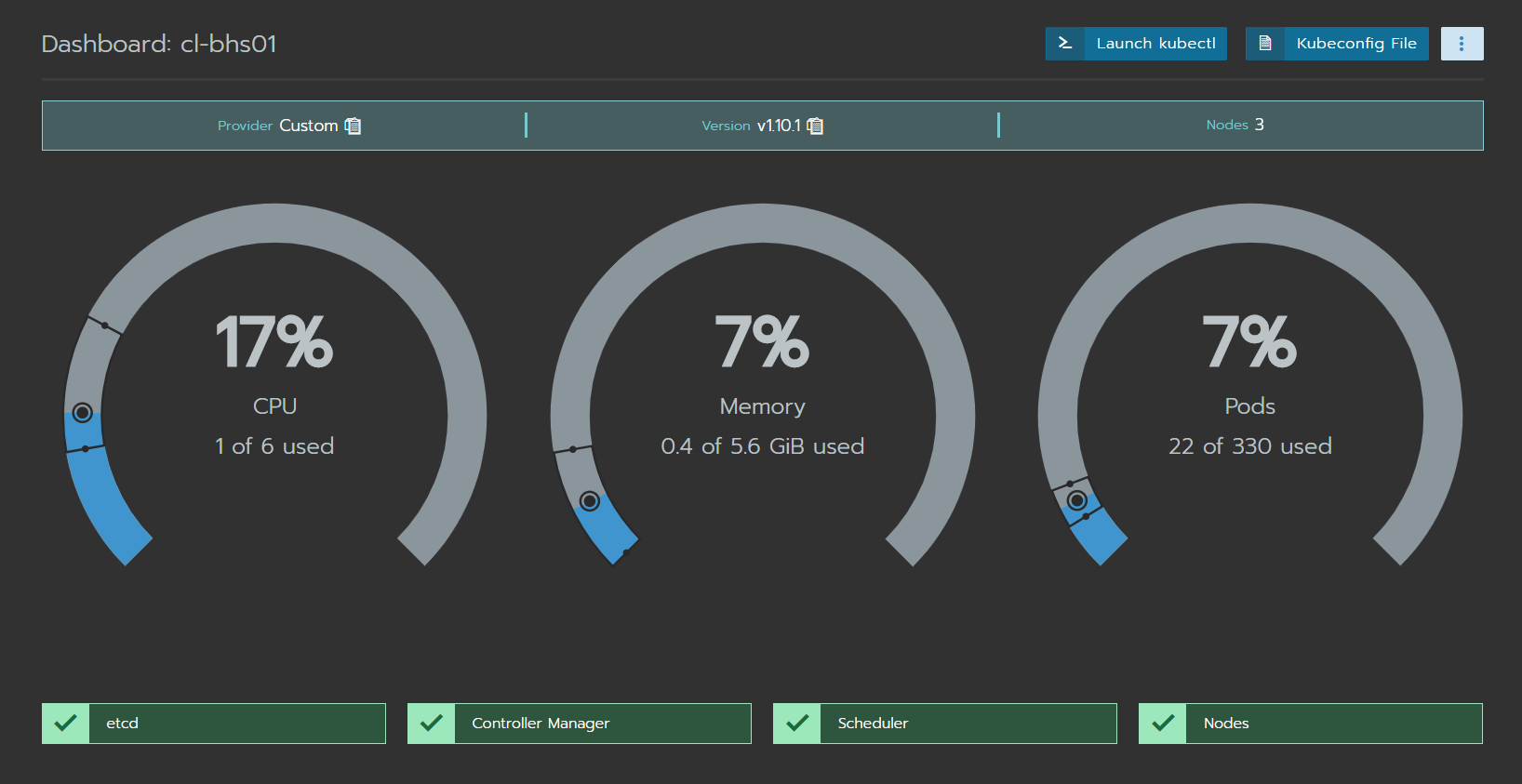
Así es como se ve un cluster de Kubernetes desde el dashboard de Rancher.
Al hacer click “Launch kubectl”, tendremos esta linda ventana que nos permitirá hacer todo tipo de operaciones usando kubectl. Otra opción es descargar el archivo de configuración, colocarlo en una maquina con kubectl para poder interactuar con el cluster de Kubernetes. Debemos tener en cuenta que de esta manera todas las operaciones son atreves del servidor con Rancher.