LACNIC31 – dia 4
Hemos tenido otra sesión de discusión sobre políticas las cuales se busca que sean aceptadas mediante consenso, vuelvo y repito, esto es un tema el cual no quiero abordar sin tener cierto conocimiento de como es el proceso de aplicación y aprobación de estas, más adelante será.
https://www.lacnic.net/3635/49/evento/agenda-lacnic-31#miercoles-fpp
A las 11:30 inicio el FTL (Foro Técnico de LACNIC), recomendado para todos aquellos apasionados a las tecnologías como yo.
Aquí una lista de los temas presentados en el FTL y un pequeño comentario personal:
Introducción Foro Técnico de LACNIC
Esta es la presentación y que pasa en el FTL, también aprovecharon para invitar a otros a que participen en esta iniciativa de LACNIC.
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/presentacion-ftl-2019.pdf
Video: https://youtu.be/ZGkDtoqvAIk
Problemas de seguridad del mundo real en una nube pública
Muchos de los problemas presentados aquí son conocidos y si no me equivoco existen implementaciones para mitigar ataques ya sean internos o externos, siendo los ataques internos (otro tenant o un empleado furioso) los más difíciles de detectar.
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/charliekaufman.pdf
Video: https://youtu.be/HyGqL5YIfxc
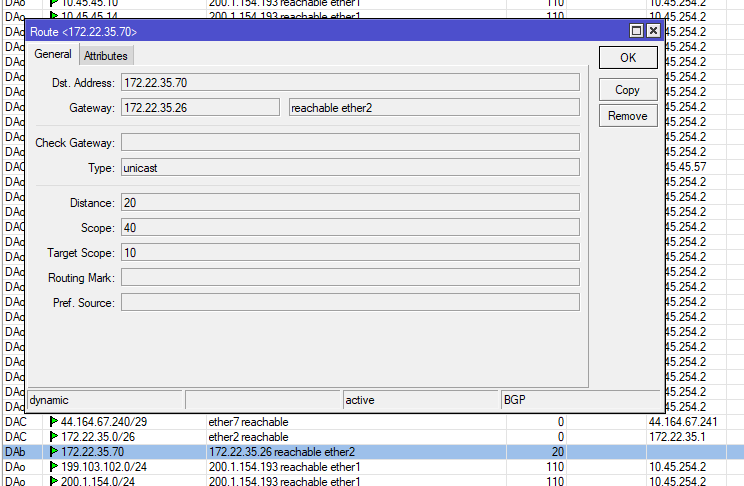
UpDown RPKI LACNIC
Super interesante presentación sobre la funcionalidad UpDowm de RPKI, necesito investigar un monto sobre y esto y de posibles automatizaciones con BIRD y RouterOS que son las plataformas de enrutamiento que actualmente estoy usando.
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/12-updown_rpki_lacnic.pdf
Video: https://youtu.be/RP6ePaLcp-Q
Juntos es posible, el paradigma de compartir los costos
Una presentación la cual me deja pensando y me apena, aquí podemos ver como se logra completar un proyecto que aporta a una nación de manera gigantesca, un IXP es parte de la infraestructura necesaria para que un país pueda sostenerse en caso de incidentes que afecten enlaces internacionales, lamentablemente, en RD tenemos poco interés en resolver este tema.
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/63-juntos.pdf
Video: https://youtu.be/2QveRcIPOCw
Automatización de listas de prefijos en peering BGP – Cómo hacerlo y su importancia
Excelente presentación donde nos muestran herramientas para crear de manera automática las listas que usaremos en los filtros de BGP y así poder controlar anuncios recibidos por ASN conectados al nuestro. Usando IRR como fuente de información se crean listas para permitir que una subred sea anunciada a otros o aceptadas por nosotros mismos.
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/48-lacnic31-douglasfischer_automatizacaodelistasdeprefixosbgp.pdf
Video: https://youtu.be/qBD7zCnbTF4
Privacidad en DNS
Esta demostrado que cada día la información generada por un computador es de mucho valor para terceros, soy muy participe de exponer lo mínimo de mi información personal al Internet, muchas veces se expone esta información de manera voluntaria, pero en otras ocasiones somos víctimas de técnicas para colectar dicha información.
Estas técnicas son desconocidas por muchas personas y es difícil entender porque deben hacer cambios en sus redes si todo esta funcionando bien. Personalmente no utilizo DNS de terceros, esta presentación me da mas razones para seguir corriendo mis propios DNS y apunarlos a los root zones sin necesidad de un resolver de una entidad la cual puede usar mi información para sacar beneficios.
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/fgont-lacnic-ftl2019-dns-privacy-final.pdf
Video: https://youtu.be/Gq_QHu8mCQs
Servicios de información de RIPE NCC para operadores
Desde hace alrededor de dos anos estoy usando varias herramientas de RIPE NCC, una de estas es RIPE Stats ( https://stats.ripe.net ), mucha información interesante desde el punto de vista curioso y mucho mas del punto de vista técnico.
https://stat.ripe.net/AS207036#tabId=at-a-glance
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/lacnic-31-en_comms-3.pdf
Video: https://youtu.be/cpIQOaA4bI0
BSDRP – Una opción de softrouter con FRR
Este es un viejo conocido y mucho mas aun porque esta basado en el sistema operativo que mas me ha gustado en todo el tiempo que he usado OpenSource, FreeBSD.
BSDRP es un proyecto fundado por la misma persona que una vez trabajo en FreeNAS. Este señor es un maestro en los equipos de embebidos.
Algo que tenia ganas de preguntar es porque uso FRR y no BIRD, no quería montar un flame-war 😊
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/4-bsdrp-lacnic31.pdf
Video: https://youtu.be/8DdtN_fj_uQ
RIPE Atlas Anchors en Máquinas Virtuales
Atlas, una plataforma que aporta un montón para un operador de redes, lamentablemente en RD ahí poco compromiso con este tipo de iniciativa.
Hace más de dos años que tengo un corriendo detrás de mi ASN (AS207036), he solicitado otro para ponerlo detrás de CLARO (AS6400).
https://atlas.ripe.net/probes/?search=&status=&af=&country=DO
Aquí se pueden ver los desplegados en DO y la gran cantidad de probes abandonados.
https://atlas.ripe.net/probes/28779/ – aaNetworks Probe – parece que tener que renombrarlo a Probe1
Presentación: https://www.lacnic.net/innovaportal/file/3635/1/ripe-atlas-virtual-machine-anchors-lacnic-31_last.pdf
Video: https://youtu.be/A7AvGVayQAA